Metadata Project
By Helen Nissenbaum, Katherine Strandburg, Kiel Brennan-Marquez and Paula Kift
With generous support from the Digital Trust Foundation
Overview
In the wake of Edward Snowden’s disclosures, the distinction between data and so-called “metadata” has featured prominently in public debate about the legality of state surveillance programs. Similar distinctions, such as “content” v. “non-content” information, have surfaced throughout U.S. privacy law, both constitutional and statutory. In practice, the purpose of these distinctions is often to insulate surveillance from judicial scrutiny. When surveillance relates only to “metadata,” the argument goes, there should be less cause for alarm.
Many commentators have criticized the substantial erosion of privacy that this style of argument enables in a world of big data, smart devices, and constant connectivity. We certainly agree with the spirit of these criticisms. Nonetheless, we also believe that important conceptual, empirical, and normative intuitions lie behind the data / metadata divide. The distinction is not meaningless. There is something to it — the question is what that “something” is. In this project, we tackle that question from a variety of perspectives. First, to set the historical and sociological backdrop, we examine the evolution of “metadata” as a term of art. Second, we explore two constitutional avenues — the Fourth Amendment, and the First Amendment — for constraining metadata surveillance. Third, we analyze relevant developments in U.S. statutory law, especially the USA FREEDOM Act, ratified in 2015 partly in response to criticism of the data / metadata framework. Our findings so far, as well as a list of issues we are continuing to pursue, are summarized below.
The Conceptual Genealogy of "Metadata"
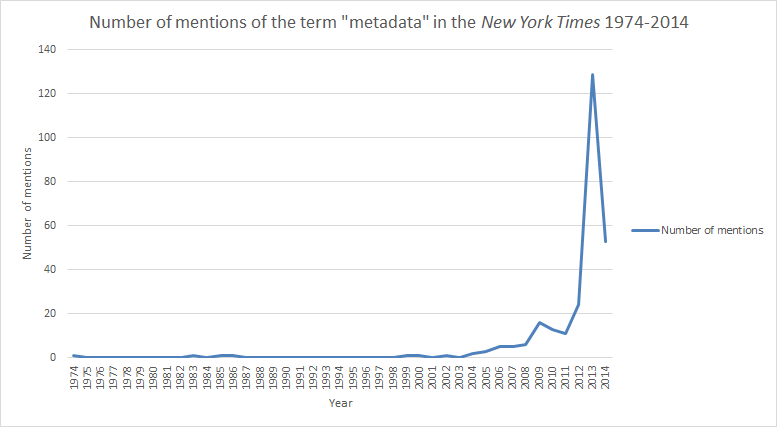
“Metadata” is a term of relatively recent vintage. It seems to have made its first appearance in popular discourse in the New York Times in 1974, in the context of a short film of the same name that was shown at the Film Society of Lincoln Center’s “Movies in the Park” series. Further mentions of the term were few and far between for the next thirty years. When the term was used during that period, it was generally in the context of computer science — e.g., metadata as a way of tagging and thus organizing knowledge - or new technologies — e.g., adding location data as metadata to digital photographs. Between 1973 and 2005, the term metadata came up in New York Times articles a meager 11 times. The language used to describe metadata in the Times in these cases was mostly neutral or positive, until about late 2005, as people began to realize that metadata could significantly, and somewhat invisibly, contribute to one’s trail of digital fingerprints. Metadata was first mentioned in connection with the National Security Agency (NSA) in 2006, when the Times explained that intelligence agencies increasingly used network analysis to figure out whom to target for further surveillance and investigation. While the NSA scandal of late 2005, which inspired that particular article, involved what is now commonly called telephony metadata, the term metadata was not employed by the Times, perhaps indicating that it was perceived as too technical for the general public at the time or reflecting the fact that the term was not generally used in previous literature about communications surveillance, which commonly referred to “traffic data” instead. In the aftermath of the Snowden revelations, use of the term “metadata” in New York Times articles skyrocketed, however, from 24 mentions in 2012 to 129 in 2013, demonstrating that “metadata” has come to resonate, at some level, with the general public.
Though the term metadata is now well-ensconced in popular discourse, how exactly it is defined, along with the value judgment attached to the term, continues to vary significantly. Some authors simply defined metadata by describing it as “communications logs,” “the data and duration of calls and the phone numbers involved in a call,” often as distinct from the content of calls. This usage echoed remarks from the government, and from the intelligence community, assuring the public that metadata concerned phone numbers and call duration, but not the content of the calls. As President Obama said in a press conference in the immediate aftermath of the Snowden revelations, “nobody is listening to your calls,” thereby suggesting not only that metadata is distinguishable from the communications content, but also that metadata is non-sensitive information, the collection of which should not raise any privacy concerns. Some articles, however, challenged this characterization. As the New Yorker pointed out in several articles (see, e.g., here, here and here) the government can infer a significant amount of information about citizens from studying their communications metadata. (Indeed, the ability to make such inferences is precisely the point of collecting it.) Recognizing this, in mid-June 2013 the New York Times Editorial Board described the government’s surreptitious metadata surveillance program as a “threat to democracy”.
The air of ambiguity in mainstream discussion of metadata is not surprising. The term is unavoidably — and perhaps deliberately — amorphous. Semantically, “metadata” describes a relationship, rather than an intrinsic property: a piece of information qualifies as “metadata” only because of its relationship to another piece of information that qualifies as “data.” (In Metadata In Context: An Ontological and Normative Analysis of the NSA’s Bulk Telephony Metadata Collection Program, Paula Kift and Helen Nissenbaum elaborate on this point at some length.) In some sense, then, nothing is intrinsically “metadata.” The designation is entirely dependent on context.
In U.S. case law, the term “metadata” does not appear until 2013, after the Snowden revelations spurred numerous challenges to the government’s construction of its surveillance powers under Section 215 of the Foreign Intelligence Surveillance Act (FISA). Though some courts have acknowledged the term’s slipperiness — for example, the Third Circuit recently wrote that “there is no general answer” to the question of what constitutes metadata — most have simply treated everything other than traditional “content” as “metadata,” without any deeper theory of the concept.
The Fourth Amendment Implications of Metadata
The Fourth Amendment implications of the data / metadata divide have been a significant focus of our study.. During the 2015-2016 academic year, we produced two papers on the topic. The first is Metadata In Context, referenced above. In that paper, Paula Kift and Helen Nissenbaum argue that invocations of “metadata” often aim to deflect attention from normative questions at the heart of Fourth Amendment law, including, but not limited to, an assessment of the social contexts in which information sharing and information surveillance occur. The findings of the paper were presented at both the Amsterdam Privacy Conference in the fall of 2015 and a workshop at the Oxford Internet Institute (OII) in the spring of 2016. The second paper, Fourth Amendment Fiduciaries, explores similar themes. There, Kiel Brennan-Marquez argues that Fourth Amendment protections for shared information should depend (and in past case law, have implicitly depended) on the relationship between the sharing party and the recipient party. While in some contexts, it makes sense to argue that if A shares information with B, A loses her expectation of privacy in the information, the argument ceases to make sense when the nature of A and B’s relationship is such that B holds A’s information “in trust.” Both Metadata In Context and Fourth Amendment Fiduciaries draw inspiration from previous work by Katherine Strandburg on the impact of technological change on Fourth Amendment doctrine — most notably, Home, Home on the Web and Other Fourth Amendment Implications of Technosocial Change.
The First Amendment Implications of Metadata
Another major focus of our study has been the First Amendment implications of the data / metadata distinction. We had the privilege to present work in progress on this topic at the 2016 Internet Law Works-in-Progress Conference at New York Law School, and are continuing to pursue related themes during the 2016-2017 academic year.
The relationship between metadata surveillance and the First Amendment — indeed, the relationship between all surveillance and the First Amendment — is complex. This is due primarily to two factors. First, the harms that normally anchor surveillance challenges to the First Amendment are “chilling effects,” as in: surveillance activity X discouraged Person A from exercising his or her First Amendment rights. Courts have been irresolute about what it means for surveillance to chill expression — both as a matter of principle, and as applied to particular cases, in terms of the concrete effects that plaintiffs who challenge surveillance on First Amendment grounds are obligated to show. Second, even in cases where surveillance clearly has chilling effects, those effects often bear on “association” rather than “expression.” What is chilled, in other words, is people’s participation in groups (often religious or political groups), rather than individual acts of speech, writing, and other traditional forms of expression. Although freedom of association is strongly protected by the First Amendment (see e.g., Boy Scouts of America v. Dale), freedom of association has received much less attention from both courts and scholars than freedom of expression, particularly as it plays out in a world of digital communication and “big data” analysis.
In two previous papers — Freedom of Association in a Networked World: First Amendment Regulation of Relational Surveillance and Membership Lists, Metadata, and Freedom of Association’s Specificity Requirement — Katherine Strandburg has argued that metadata surveillance programs are subject to First Amendment strictures and that indiscriminate bulk collection and use of communications metadata violate First Amendment tailoring requirements, even under existing “freedom of association” jurisprudence. More work remains to be done, however, to determine exactly when a metadata surveillance program should be deemed to violate the First Amendment and how such programs must be tailored to comply with First Amendment strictures. For example, should a surveillance program be constitutionally suspect simply because it makes it possible for the government to draw (too many) sensitive inferences about private associations? Or should plaintiffs have to show that such inferences have been drawn? Even if the latter approach is appealing in principle, it may be difficult to define and implement an effective “association-sensitive use restriction” in practice. What level of suspicion should be required, for example, to justify government collection and use of metadata to investigate associations among individuals or within groups? These are among the questions we are continuing to pursue in ongoing work on this project.
The Statutory Side of Metadata
The principle behind the data / metadata distinction — that people have a greater interest in the content of transmitted information than they do in “everything else” surrounding the transmission — has long informed U.S. statutory law. The Electronic Communications Privacy Act (ECPA), 18 U.S.C. § 2510-22, ratified in 1986, distinguishes the content of electronic communications (18 U.S.C. § 2510(8)), whose interception generally requires a probable cause warrant, from dialing, routing, and address information (18 U.S.C. §§ 3127(3) and (4)), whose collection only requires a court order based on relevance to an ongoing investigation. The Foreign Intelligence Surveillance Act (FISA), 50 U.S.C. § 1801 et seq., first ratified in 1978 and continually amended since (especially after September 11th), makes a similar distinction. FISA requires a probable cause warrant for electronic surveillance (see 50 U.S.C. § 1805(a)(2)(A), 50 U.S.C. § 1801(a)(4)), at least when there is “substantial likelihood that the surveillance will acquire the contents of any communication to which a United States person is a party” (50 U.S.C. § 1802(a)(B)). By contrast, to obtain a court order for dialing, routing, and address information, only relevance to an authorized foreign intelligence investigation that is not “conducted solely upon the basis of activities protected by the first amendment” is required (50 U.S.C. § 1842(a)(1)).
Recent controversy over the data / metadata distinction arose when it was revealed that, following September 11th, the NSA began collecting telephony metadata on virtually every American’s calls on an ongoing basis, eventually relying on the authority of Section 215 of the USA PATRIOT Act. (50 U.S.C. § 1861). That provision authorized the Foreign Intelligence Surveillance Court to issue an order “requiring the production of any tangible things (including books, records, papers, documents, and other items)” based on “a statement of facts showing that there are reasonable grounds to believe that the tangible things sought are relevant to an authorized [foreign intelligence] investigation” that does not target a U.S. person “solely upon the basis of activities protected by the first amendment to the Constitution.”
The NSA contended that its ongoing bulk collection met Section 215’s relevance standard essentially because all telephony metadata has the potential to be useful in tracing connections between potential terrorists. This extraordinarily broad interpretation of relevance was ratified by the Foreign Intelligence Surveillance Court. Many others, including the Privacy and Civil Liberties Oversight Board, numerous commentators and advocacy organizations (see e.g., here and here), and ultimately many courts, disagreed. The Second Circuit issued a particularly harsh indictment of the NSA’s reading of Section 215, calling the amount of information over which the government claimed surveillance authority “staggering.”
Largely in response to these concerns, Congress passed the USA FREEDOM Act in 2015, effectively amending Section 215 to end the bulk telephony metadata collection program. Among other things, the amended provision addresses bulk collection by requiring orders to be based on a “specific selection term,” which will “limit, to the greatest extent reasonably practicable, the scope of tangible things sought consistent with the purpose for seeking [them]” (50 U.S.C. § 1861(b)(2) and (k)(4)). It generally retains the relevance standard, however, unless the order requests ongoing production of “call detail records.” In that case, the government must also present facts showing “reasonable, articulable suspicion” that the specific selection term (such as a phone number) is associated with an individual conducting or preparing for “international terrorism” (50 U.S.C. § 1861(b)(2)(C)).
Though these changes are, at some level, an obvious victory for privacy, many worry that they are, at best, a partial victory, and at worst a Pyrrhic one. In The Incredible Bulk - Metadata, Foreign Intelligence, and the Limits of Domestic Surveillance Reform (forthcoming), Paula Kift argues that although the USA FREEDOM Act made some headway towards limiting the scope, and improving the accountability, of domestic government surveillance programs, significant risk remains that the government can continue to collect large amounts of communications metadata of Americans that are not strictly relevant, in the usual sense, to an authorized foreign intelligence investigation. Most worryingly, the USA FREEDOM Act does nothing to close a rather large loophole. Under Section 702 of the FISA Amendments of 2008 (50 U.S.C. § 1881a) and Executive Order 12333, the government engages in bulk collection practices targeting non-U.S. persons that may have the collateral effect of sweeping up both content and non-content telecommunication records of millions of Americans. Meaningful foreign intelligence surveillance reform will thus have to address not only the distinction between data and metadata, but also the distinction between “domestic” and “foreign” communications, as well as the risks to Americans’ privacy and civil liberties associated with “incidental” data collection.
Ongoing Work
In ongoing work, this project will produce a series of law review articles addressing some or all of the five conceptual challenges involving the data/metadata distinction that have emerged from our study so far.
The first challenge is to continue to probe the normative underpinnings of the data/metadata distinction. Most recent debate centers around “communications metadata,” invoking the content/non-content distinction with its clear First Amendment overtones. But not all data is associated with communication, where the content/non-content distinction has its conceptual grounding. Other information that is often lumped in with “metadata” includes location data, commercial transaction data and financial data. It is not clear in what sense (if any), such information can be described as “metadata” in relation to any underlying “data;” nor is there a priori reason to anticipate that the normative and constitutional issues raised by government collection and use of these sorts of information are commensurate with the issues relevant to communications metadata and the content/non-content distinction.
The second challenge is to understand and delineate how the data / metadata distinction interacts with the distinction between bulk and targeted surveillance. By now, it is well documented that metadata starts to “look like data” as the quantity of collected metadata increases — and the tools used to analyze it become more powerful, raising the following important questions: Does this transformation as government moves from targeted to bulk collection reflect a general truth about privacy interests and surveillance power? Does it imply that when metadata surveillance is targeted to particular subjects, it need not be subject to heightened scrutiny? And the obverse: is bulk collection always worse than targeted collection, as some recent scholarly accounts — such as Danielle Citron and David Gray’s effort to theorize a “quantitative right of privacy” — would imply? Or are there circumstances in which bulk is better from a privacy or civil liberties perspective?
The third challenge, related to the second, is to understand and articulate whether there is something specific about metadata (or about the general categories of information of which metadata is an example) that makes bulk collection especially worrisome. Is metadata surveillance distinctive in how it seems to change when performed in bulk? Or do the issues concerning bulk metadata surveillance arise only because bulk collection of “data” is ordinarily foreclosed by constitutional or statutory requirements of probable cause, particularity and tailoring?
A fourth challenge, related to our analysis of how metadata collection programs implicate First Amendment rights, is to understand which uses of metadata are most alarming and why. Do we worry about the government monitoring everyone, or instead about the government engaging in unregulated and potentially discriminatory selective monitoring? Is the most salient risk that bulk surveillance may serve as a cover for (or at least facilitate) abusive discretionary targeting, perhaps even tracking protected categories, such as race and religion? Or is the primary concern that the government (or rogue government agents) will use bulk metadata to decide whom to target based on constitutionally or democratically unacceptable grounds?
Finally, a fifth challenge is to understand how all of these normative and conceptual questions relate to constitutional issues, such as Fourth Amendment particularity, First Amendment tailoring and due process.